
Exploring dbt with Snowflake
In this article we will see how to use dbt with Snowflake. dbt (data build tool) does the T in ELT (Extract, Load, …


In this article we will see how to initialize and configure a new dbt project for postgres database. Code used in this article can be found here.
dbt seed to load raw and reference tables just for demo purposes.dbt seed to load your raw layer, though it can be used to load simple reference tables. All other data ingestion to your RAW layer will happen outside dbt.Download and install docker for your platform. Click here for instructions
Let’s create the infrastructure required for this demo using Docker containers.
Open a new terminal and cd into dbt-docker directory. This directory contains infra components for this demo
Create a copy of .env.template as .env
Start dbt container by running
docker-compose up -d --build
Start Postgres container by running
docker-compose -f docker-compose-postgres.yml up -d --build
Validate the container by running
docker ps
Navigate to pgAdmin in your browser and login with admin@admin.com and postgres
Click on Add New Server and enter following details
✅ Name : dbt demo
✅ Host Name : postgres
✅ User : postgres
✅ Password : postgres
If you change the credentials in .env then please make sure to use them
SSH into the dbt container by running
docker exec -it dbt /bin/bash
Validate dbt is installed correctly by running
dbt --version
cd into your preferred directory
cd /C/
Create dbt project by running
dbt init dbt-postgres
Navigate into dbt-postgres directory, create a new dbt profile file profiles.yml and update it with Postgres database connection details
dbt-postgres:
target: dev
outputs:
dev:
type: postgres
host: postgres
user: postgres
password: postgres
port: 5432
dbname: postgres
schema: demo
threads: 3
keepalives_idle: 0 # default 0, indicating the system default
Edit the dbt_project.yml to connect to the profile which we just created. The value for profile should exactly match with the name in profiles.yml
From the project directory, run dbt-set-profile to update DBT_PROFILES_DIR.
dbt-set-profile is alias to unset DBT_PROFILES_DIR && export DBT_PROFILES_DIR=$PWD
Validate the dbt profile and connection by running
dbt debug
Update name in dbt_project.yml to appropriate project name (say dbt_postgres_demo)
Delete the contents from data, macros, models, tests and snapshots directories to follow along this demo
Seeds are CSV files in your dbt project that dbt can load into your data warehouse.
Copy the sample data from dbt-postgres\demo-artifacts\data to dbt-postgres\data
Review the seed configuration in dbt_project.yml. The seed configuration should have project name followed by names which should match with the structure of data directory.
seeds:
dbt_postgres_demo:
schema: raw # all seeds in this project will use the mapping schema by default
imdb:
schema: imdb # seeds in the `data/imdb/ subdirectory will use the imdb schema
sakila:
schema: sakila # seeds in the `data/sakila/ subdirectory will use the sakila schema
address:
+column_types:
phone: varchar(50)
lookups:
schema: lookups # seeds in the `data/lookups/ subdirectory will use the lookups schema
Load the seed files by running below command
dbt seed
Data will be loaded into a schema with dbt_ prefix. To fix this we will create a small macro
Macros are pieces of code that can be reused multiple times.
Copy the macros from dbt-postgres\demo-artifacts\macros\utils to dbt-postgres\macros\utils
Macro generate_schema_name uses the custom schema when provided
Seed all files by running below command
dbt seed
This time data will be loaded into the correct schema without the dbt_ prefix
Seed select files by running
dbt seed --select address
Sources make it possible to name and describe the data loaded into your warehouse by your Extract and Load tools.
We could either use ref or source function to use the data which we seeded, but to stay close to a real use case, we will use source function.
Copy the source definition from dbt-postgres\demo-artifacts\models\sources\ to dbt-postgres\models\sources\
Test sources by running below command
dbt test --models source:*
dbt packages are in fact standalone dbt projects, with models and macros that tackle a specific problem area.
Create a new file named in packages.yml and add package configuration
Specify the package(s) you wish to add
packages:
- package: dbt-labs/dbt_utils
version: 0.7.0
- package: dbt-labs/codegen
version: 0.4.0
Install the packages by running
dbt deps
Model is a select statement. Models are defined in .sql file.
Copy the model definition from dbt-postgres\demo-artifacts\models\ to dbt-postgres\models\
Review the model configuration in dbt_project.yml. The model configuration should have project name followed by names which should match with the structure of models directory
models:
dbt_postgres_demo:
materialized: table
staging:
schema: staging
materialized: view
marts:
dim:
schema: dim
materialized: table
fact:
schema: fact
materialized: table
presentation:
schema: analytics
materialized: view
Default materialized configuration can be specified at model project level. materialized configuration can be overriden at each directory level
To define variables in a dbt project, add a vars config to dbt_project.yml file
vars:
start_date: '2005-01-01'
high_date: '9999-12-31'
Build models by running below command
dbt run --models stg_sakila__customer
dbt run --models staging.*
dbt run --models +fct_sales --var '{"start_date": "2005-05-24"}'
dbt run --models +tag:presentation-dim
dbt run --models +tag:presentation-fact --var '{"start_date": "2005-05-24"}'
dbt run
Tests are assertions you make about your models and other resources in your dbt project (e.g. sources, seeds and snapshots).
Types of tests:
schema tests (more common)
data tests: specific queries that return 0 records
Generate the yaml for existing models by running
dbt run-operation generate_model_yaml --args '{"model_name": "dim_customer"}'
schema tests can be added at table level OR column level. Here is an example of test under column definition in model yaml
version: 2
models:
- name: dim_customer
description: ""
columns:
- name: customer_id
description: ""
tests:
- unique
- not_null
Execute tests by running below commands
dbt test --models +tag:presentation-dim
dbt test --models +tag:presentation-fact
-- Incremental demo
SELECT cast(date_id AS VARCHAR) as date_id
,count(1) as rec_count
FROM analytics.sales
GROUP BY date_id
ORDER BY date_id;
-- Revenue by day
SELECT ad.day_name
,af.film_rating
,ac.customer_city
,sum(amount) AS revenue
FROM analytics.sales asa
JOIN analytics.film af ON (af.film_id = asa.film_id)
JOIN analytics.DATE ad ON (ad.date_dim_id = asa.date_id)
JOIN analytics.customer ac ON (ac.customer_id = asa.customer_id)
GROUP BY (
ad.day_name
,af.film_rating
,ac.customer_city
)
ORDER BY revenue DESC limit 100;
dbt docs provides a way to generate documentation for your dbt project and render it as a website.
You can add descriptions to models, columns, sources in the related yml file
dbt also supports docs block using the jinja docs tag
Copy sample jinja docs from dbt-postgres\demo-artifacts\docs\ to dbt-postgres\docs\
Generate documents by running
dbt docs generate
Publish the docs by running
dbt docs serve --port 8085
Stop published docs by running ctrl + c
Open a new terminal and cd into dbt-docker directory. Run the below command to delete the docker containers and related volumes
docker-compose down --volume --remove-orphans
Hope this was helpful. Did I miss something ? Let me know in the comments OR in the forum section.
In this article we will see how to use dbt with Snowflake. dbt (data build tool) does the T in ELT (Extract, Load, …
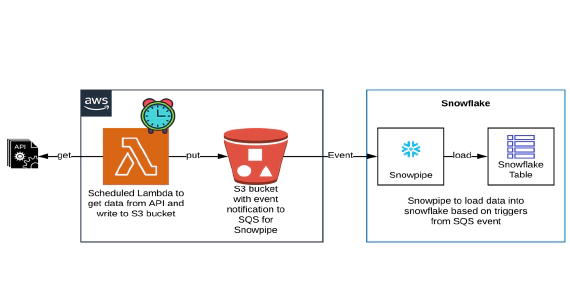
In this article we will see how to get/pull data from an api, store in S3 and then stream the same data from S3 to …