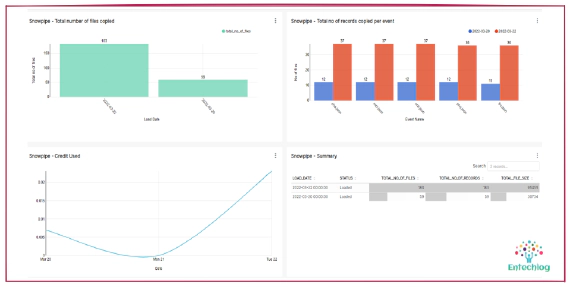
Visualizing Snowpipe usage with dbt and Superset
Snowpipe is Snowflake’s continuous data ingestion service. Snowpipe loads data within minutes after files are …


A Snowflake object naming convention is a framework for naming objects in a way that describes what they contain and how they are used, following a standard naming convention helps to formalize expectations and to promote consistency with its users. It’s a good practice to introduce these naming conventions when starting a new implementation, but if you already have an environment without a standard naming convention, it’s better late than never. Objects in Snowflake can be classified into account level objects and schema level objects. Here are some common account and schema level objects

We will see how to name account-level objects, i.e. non-database objects such as users, roles, warehouses, database, etc.
In the Snowflake world, often multiple environments are hosted in the same account. We will add an environment prefix to differentiate them. Having the prefix will group the objects by environments. Some common environment prefixes are DEV, [SIT, UAT, TEST, QA, STG], CICD, PRD. Having a prefix is recommended for database names and on the rest of the objects you can add them based on your use case.
Alternate option instead of using prefix to differentiate environments would be creating multiple accounts, but this also mean
User name is the unique identifier for the user in Snowflake. It is not the user’s login name (i.e. the name the user enters when logging into Snowflake). Snowflake allows users to have different user names and login names, if desired. We can classify accounts as , user accounts are used by real users, service accounts are used by system services.
| Naming Rule | [EMAIL] |
|---|---|
| Description | Preferable to use email address for creating the users as it will be unique within an organization |
| Example | user@example.com |
| Required Privilege | USERADMIN |
| Naming Rule | [ENV]_[PROJECT/PROGRAM]_[APP_CODE]_USER |
|---|---|
| Description | Environment prefix followed by project/program short code, application name or short code and _USER postfix |
| Example | DEV_ENTECHLOG_ATLAN_USER |
| Required Privilege | USERADMIN |
Roles are the entities to which privileges on securable objects can be granted and revoked. Roles are assigned to users to allow them to perform actions required for business functions in their organization.
In USER roles we will not have the environment prefix. Idea here is to have minimal roles and to control the access to different environments using grants. In SYSTEM/SERVICE roles it’s good to have the environment prefix so access is not shared between environments.
| Naming Rule | [PROJECT/PROGRAM]_[ROLE_NAME]_ROLE |
|---|---|
| Description | Project/program short code, role an user will play in the project and _ROLE postfix |
| Example | ENTECHLOG_ANALYST_ROLE ENTECHLOG_DEVELOPER_ROLE ENTECHLOG_DBT_ROLE |
| Required Privilege | USERADMIN |
A virtual warehouse, often referred to simply as a “warehouse”, is a cluster of compute resources in Snowflake. A warehouse provides the required resources, such as CPU, memory, and temporary storage, to perform the following operations in a Snowflake session.
It’s good to have a one to many relation between roles and warehouse, by that way for each role so there is at least one default warehouse and no shared resource usage/limits. Currently it’s not possible to assign a default warehouse to a role, so this is not enforced automatically rather a practice that should be followed. This also helps to give a better breakdown for each warehouse usage. The key here is to make sure only the corresponding roles have access to the warehouse to avoid roles sharing warehouses unless that is something you need by design to save cost and to reduce the overhead in managing multiple warehouse.
| Naming Rule | [ENV]_[PROJECT/PROGRAM]_[ROLE_NAME]_[WH_SIZE] |
|---|---|
| Description | Environment prefix followed by project/program short code, warehouse size identifier and role which uses the warehouse |
| Example | ALL_ENTECHLOG_ANALYST_WH_S ALL_ENTECHLOG_ANALYST_WH_M ALL_ENTECHLOG_ANALYST_WH_L DEV_ENTECHLOG_DBT_WH_S DEV_ENTECHLOG_DBT_WH_M DEV_ENTECHLOG_DBT_WH_L DEV_ENTECHLOG_DBT_WH_XL |
| Required Privilege | SYSADMIN |
Here user roles like ANALYST have warehouses which are shared for all environments, but system roles like DBT have different warehouses for different environments. Most often batch cycles in these environments will have schedule overlap and isolated warehouses ensure there is no impact on production processes because of a bad query from the user OR TEST environment is consuming all resources.
A database is a logical grouping of schemas. Each database belongs to a single Snowflake account.
| Naming Rule | [ENV]_[PROJECT/PROGRAM]_[DATA_LAYER]_DB |
|---|---|
| Description | Environment prefix followed by project/program short code, name for the data layer and _DB postfix |
| Example | DEV_ENTECHLOG_RAW_DB DEV_ENTECHLOG_CONFORMED_DB OR DEV_ENTECHLOG_STAGING_DB DEV_ENTECHLOG_CURATED_DB OR DEV_ENTECHLOG_DW_DB DEV_ENTECHLOG_SEMANTIC_DB OR DEV_ENTECHLOG_METRIC_DB |
| Required Privilege | SYSADMIN |
Using environment prefix in object names can be limited to the account level objects only. In schema level objects, the same name can be used across all environments unless you have a strong reason to host multiple environments in the same database.
A schema is a logical grouping of database objects (tables, views, etc.). Each schema belongs to a single database.
| Naming Rule | [DATA_GROUPING] |
|---|---|
| Description | The grouping could be by source name OR by normalization technique |
| Example | DEV_ENTECHLOG_RAW.HUBSPOT DEV_ENTECHLOG_RAW.SALESFORCE DEV_ENTECHLOG_STAGING_DB.DIM DEV_ENTECHLOG_STAGING_DB.FACT DEV_ENTECHLOG_DW_DB.DIM DEV_ENTECHLOG_DW_DB.FACT DEV_ENTECHLOG_METRIC_DB.PRODUCT |
| Required Privilege | CREATE SCHEMA |
| Object Type | Naming Rule | Example |
|---|---|---|
| Table | [TABLE_NAME] | DEVICE |
| View | [VIEW_NAME] | DATE |
| Integration | [NAME]_[TYPE]_[SUB_TYPE]_INT | MOCKAROO_API_AWS_INTG MOCKAROO_STR_S3_INTG MOCKAROO_NOT_SQS_INTG MOCKAROO_SEC_SCIM_INTG |
| File Format | [NAME]_[FORMAT]_FF | MOCKAROO_XML_FF |
| Stage | [NAME]_[TYPE]_STG | MOCKAROO_S3_STG |
| Snowpipe | [NAME]_PIPE | MOCKAROO_PIPE |
| Stored Procedure | [NAME]_SP | MOCKAROO_SP |
| Stream | [NAME]_STREAM | MOCKAROO_STREAM |
| Task | [NAME]_TASK | MOCKAROO_TASK |
Hope this was helpful. Did I miss something ? Let me know in the comments OR in the forum section.
This blog represents my own viewpoints and not of my employer, Snowflake. All product names, logos, and brands are the property of their respective owners.
Snowpipe is Snowflake’s continuous data ingestion service. Snowpipe loads data within minutes after files are …
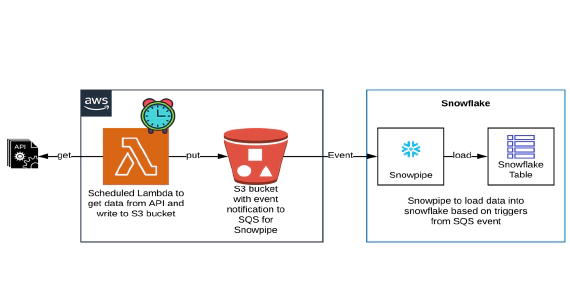
In this article we will see how to get/pull data from an api, store in S3 and then stream the same data from S3 to …